Creating a Database From
Spreadsheets
This post is
inspired by my recent work with a client, where we navigated the transition from bunch of
spreadsheets to a database system to accommodate their growing data needs and ambitions. I'll
explore the two main approaches to data storage and management: databases and spreadsheets,
highlighting their differences and when it's right time to move your data to a database. From
this experience I'll also present a migration pipeline, share 8 valuable tips and showcase an
example with code similar to what we implemented. For any feedback or inquiries, feel free to reach
out!
Relational Data
Model
Let’s first look at the most ubiquitous way to organize or
store data. It’s the table format and is queried by SQL. This dated way back in the early 70s and
still leads the world of databases by far. It relies on the relational data model that defines a
relation as a set of tuples. Each tuple represents a row and a collection of rows in the same domain
forms a table. Like numbers can be manipulated with operations like adding or multiplying the
manipulation between these relations is mathematical operations from set theory. Relational Database
Management Systems (RDBMS) builds upon this foundation and also guarantees ACID properties.

ACID properties can be explained simply by
banking example:
Atomicity guarantees that a transaction either fully occurs
or not. When you send money to your friend, either the full amount is transferred out or none
Consistency ensures validity. When you send money the total amount should not be
changed, meaning no amount of money within a system appears or disappears
Isolation means concurrent transactions do not interfere with each other and a
process updates the system at a time. Imagine two people making $70 spending on a $100 account
simultaneously, isolation ensures only one can make the transaction
Durability is the guarantee that the successful transactions are permanent. If you
deposit money to your account just before a power outage in the bank that amount will persist when
the system is back up.
Relational databases are the most common way to organize and manipulate
data because they provide data integrity with ACID properties and any query relies on the
mathematical foundations with decades old optimization efforts.
Cell Structured Data Model
Spreadsheets
are another way to store tabular formatted data but with much more relaxed requirements. The format
of a spreadsheet is cell structured data model, each cell is defined by its row and column and
attains a value individually. Users can still define a relationship between cells but it’s not
enforced. This brings flexibility to users so that the restrictions in RDBMS are gone. It is
accessible to most, user friendly environment making spreadsheets the most widely used kind of
software for businesses. It is a great tool for leveraging simple calculations and storing small
amounts of data (<1M rows). The problem starts when businesses use spreadsheets to integrate into
their processes and probably need to limit the data format to ensure integrity.
When to Use Databases Instead of
Spreadsheets?
There are several reasons to not use spreadsheets and move to a
relational database. I’ll list some of them from my experience:
Scalability.
Data can scale vertically with more rows of data, or horizontally with more related tables,
therefore more attributes. Spreadsheets can accommodate certain limits of rows and columns and
defining relations among sheets can be frustrating because it’s not designed to have complex
relations among the other sheets. Spreadsheets do not scale as well as the volume and the complexity
of data rise up.
Response Time. More data and more relations among the
attributes/cells within the sheets or among other sheets make manipulating data slower. The velocity
of analysis can be crucial for many business purposes.
Automation. Whether
it’s AI automation or RPA, data is required to move around by the systems called data pipelining.
Spreadsheets are not meant to move data in or out. Some services make this possible but it’s not a
viable choice comparing it with an RDBMS.
Security. Many spreadsheet
software grant access roles to users but comparing it with databases it’s simple like read/edit.
Databases grant user-specific roles and they can encrypt sensitive data. These roles can be extended
with file transmission protocols enabling a secure sharing environment.
Data
Integrity. Spreadsheets are flexible enough that a user can make mistakes filling cells
with inconsistent values or types. The transactions are not fully ACID compliant in spreadsheets,
which may lead to data integrity problems. Of course, if all the above listed are not your concern,
you might use spreadsheets in your business applications. In fact, many times spreadsheets are the
best way to go. Especially when there should be no preset structure of data, no attribute type, or a
very small amount of data to make simple calculations. Cell structured data model brings its
advantages focused on more flexible and presentable functionalities, like filling a cell with color
for soft deleting.

8 Tips for Migrating from Spreadsheets to
Databases
Here are my tips and caveats on migration from spreadsheets to
RDBMS:
1- Design the destination schema. ER diagram illustrates the table’s
attributes and how the relations among the tables are defined among these attributes. This part is
important if there are many sheets that are related to each other
2- Find the
data points specific to the cell structured data format and add them as a column if necessary. For
example I mention the color filling, my clients fill a row that shouldn’t be used for their
application. This is a way to soft delete an element. A simple Excel function can transfer this
information into a column, like an isDeleted column with a boolean value
3-
Transform data to a tabular structure (normalize) if needed. RDBMS requires data to be in a tabular
format but normalizing data brings its own problems. Deciding which normal forms to be loaded into a
database requires evaluating the tradeoffs of using NFs. mainly the tradeoff I had was redundancy vs
complexity, since there are no storage problems and low macros, data duplication happened to
normalize. Be careful with normalizing the merged cells
4- Data types might
not always align. First of all spreadsheets do not enforce a common type under a column, so defining
a data validation function within a column or just formatting the column might be required. If there
are multiple sheets to be merged make sure they’re the same type, otherwise SQL’s union function
will raise an error. Also when determining the type of the table when creating from a spreadsheet,
make sure to write DDL from scratch, defining the data types directly from the spreadsheet
itself
5- Make sure to define primary keys, if there is not a unique value
for each column, then it can be added before loading it to a database. I used python’s uuid library
to add a unique identifier to each column and make that a primary key for the table
6- Exporting data to csv or other formats might lose some of the information within
the data, especially the ones specific to cell structured data format. The example I gave before,
filling the cell with color, or strikethrough a text, is out of the limitations of csv format. There
are special connectors for extracting all the information within a spreadsheet. I used pygsheets for
Google Sheets to transform data in Python. You also need to enable Google’s Sheets API and authorize
it to extract the data from the Sheets.
7- Some databases do not accept
special characters. There should be a mapping between special characters to UTF-8. In my case, I map
Turkish characters to English ones with a simple dictionary.
8- Indexing and
cleaning could be necessary for the organization. My connector took empty spaces as well, strangely
taking different numbers of empty columns from the same structured sheets. I don’t know the exact
reason but it could be about the used cells previously. I drop the columns with no values to union
all the sheets in the same context. The same structured sheets may also have different starting
points, when ingesting it all in a loop I put a try-except-finally statement to overcome this
Data Pipeline Orchestration
There are 30
times more people who know how to use a spreadsheet than to write SQL. It’s surely more common and
easier to adapt and that’s why it’s a must-have for most business units. It’s either moving data
from a spreadsheet or loading the result of a query to a spreadsheet for business people to work on,
the process of moving data from source to destination is required. So far I have written about
migrating data from spreadsheets to databases but sometimes we need a constant transfer of data in
either way as batches. The process of transferring data from a source to a destination is called
data pipelining. In the past cron jobs were state of art for scheduling the transfer of data but as
the volume and variety of data increased and storage systems advanced, so we developed more advanced
ways to work with them. These modern frameworks are called orchestration tools and they let the user
build, schedule, and monitor the data pipelines. Extraction can be from different sources with
predefined requirements thus making the data flow more granular. It can be parameterized and
configured to reuse. For my use case, I used Prefect as an orchestration tool. It defines each
pipelining action as a task and then lets the user manage the sequence by organizing tasks into a
workflow. Users can decide how to take action when a task fails, the number of retries, log and
handle the errors.
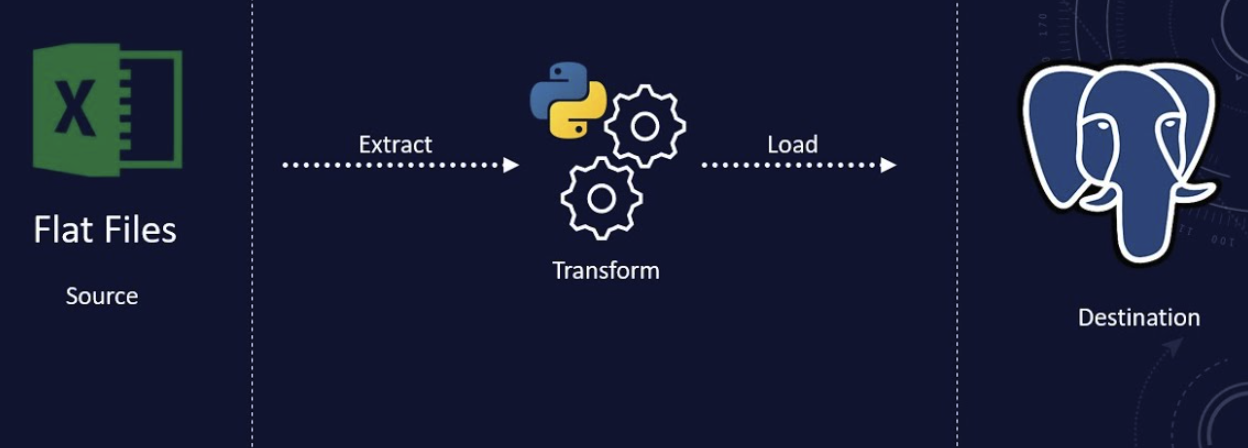
Example Use Case with Code
Let’s say that
we’re building a database of marketing channels. Each channel and its metrics are stored in a
separate sheet in Google Sheets and financial tables are stored in Excel files. The aim is to make a
data pipeline that takes the local Excel files and Google Sheets from API, and then sends merged
data to Bigquery Data Warehouse.
1- Define extraction tasks from the local file system and
GSheets API, and save it to a dataframe
@task
def extract_from_gsheets(sheet):
gc = pygsheets.authorize(service_file='cred_sheets.json')
combined_data = pd.DataFrame()
data_dict = {}
for i in range(14):
sh = gc.open(sheet_name)
wks = sh[i]
data = wks.get_as_df(start='A1', include_tailing_empty=False, headers=1).reset_index(drop=True)
data.name = wks.title
data = data.drop(columns=[col for col in data.columns if col == ''])
data_dict[wks.title] = data
combined_data = pd.concat(data_dict.values(), ignore_index=True)
return combined_data
2- Then transform the data by converting it to a suitable
encoding, adding primary keys if they lack, rearrange columns, etc.
@task
def transform_data(combined_data):
combined_data['id'] = [uuid.uuid4().hex for _ in range(len(combined_data))]
cols = list(combined_data.columns)
cols.insert(0, cols.pop(cols.index('id')))
combined_data = combined_data.rename(columns=replace_turkish_chars)
combined_data = combined_data[cols]
return combined_data
3- Load it to the DW via an endpoint
@task
def load_to_postgres(transformed_data):
engine = create_engine(f'postgresql://{postgres_user}:{postgres_password}@{postgres_host}:{postgres_port}/{postgres_db}')
transformed_data.to_sql('Tutors', engine, if_exists='append', index=False)
4- Build the data flow by organizing these tasks specifying how
frequent the workflow starts or which events triggers the flow
5- This flow can be deployed
locally or to Prefect Cloud
@flow(name="ETL - Google Sheets to PostgreSQL", log_prints=True)
def etl_flow():
data = extract_from_gsheets(sheet_name)
transformed_data = transform_data(data)
load_to_postgres(transformed_data)
etl_flow()
if __name__ == "__main__":
etl_flow.serve(name="my-first-deployment",
tags=["onboarding"],
interval= 3600)